How to design an MD5 verifier
项目地址:https://github.com/fishcanf1y/MD5-Checker
Description:
MD5 校验器用于验证数据完整性和检测数据是否被篡改,常用于文件下载、软件更新、密码存储等场景。它可以快速生成文件的“数字指纹”——MD5 值,然后将该值与原始值进行比较,以确保文件在传输或存储过程中没有发生变化。
以下是MD5 校验器的主要用途和优势:
文件完整性验证:
当下载文件时,网站通常会提供文件的MD5 值。下载完成后,用户可以使用MD5 校验器计算下载文件的MD5 值,并与提供的MD5 值进行比较。如果两者一致,则表示文件没有损坏或被篡改;如果不一致,则表示文件可能损坏或被恶意修改,需要重新下载。
数据一致性验证:
在数据传输和存储过程中,可能会出现错误或干扰导致数据损坏。通过对数据进行MD5 校验,可以确保数据在不同节点之间的一致性,防止数据丢失或损坏。
安全性保护:
MD5 校验可以用于检测恶意篡改。如果文件在传输过程中被恶意篡改,其MD5 值会发生变化,从而可以及时发现并阻止恶意行为。
文件识别和重复性检测:
每个文件都有一个唯一的MD5 值,可以用于快速识别文件,避免存储和传输重复文件,节省存储空间和带宽。
密码存储:
虽然MD5 算法不再被推荐用于直接存储密码,但它仍然被广泛用于存储密码的哈希值。这样即使数据库泄露,攻击者也无法直接获取用户的明文密码。
总而言之,MD5 校验器在保证数据安全和完整性方面发挥着重要作用,尤其是在文件传输、数据存储和密码管理等场景中。
How To Do?
以下我将梳理大致思路并列举一些代码片段来说明其作用
一、核心目标
- 核心功能:
- 计算文件的MD5哈希值(文件完整性指纹)
- 验证文件是否与预期MD5匹配
- 支持批量处理和目录递归操作
- 非功能性需求:
- 内存安全(支持大文件处理)
- 跨平台兼容性(Windows/Linux/macOS)
- 符合标准工具行为(兼容
md5sum格式)
二、关键实现思路
1. 文件哈希计算(核心算法)
设计要点:
- 分块处理:避免内存溢出
def calculate_md5(file_path, block_size=65536):
md5 = hashlib.md5()
with open(file_path, 'rb') as f:
for block in iter(lambda: f.read(block_size), b''):
md5.update(block) # 增量更新哈希
return md5.hexdigest()使用生成器模式逐块读取(
iter+lambda技巧)默认64KB块大小平衡I/O效率和内存占用
错误处理:
- 捕获
IOError并返回None统一表示失败 - 二进制模式(
'rb')确保跨平台一致性
- 捕获
2. 验证机制
设计要点:
- 大小写不敏感:
.lower()处理用户输入
if actual_md5.lower() == expected_md5.lower()明确输出:格式化显示预期/实际值对比
返回布尔值:便于脚本化调用
3. 批量处理
递归目录处理:
for root, _, files in os.walk(directory):
for filename in files:
file_path = os.path.join(root, filename)
relative_path = os.path.relpath(file_path, directory)- 使用
os.walk实现深度优先遍历 os.path.relpath生成相对路径保证校验文件可移植性
4. 命令行接口
子命令模式:
subparsers = parser.add_subparsers(dest='command')
calc_parser = subparsers.add_parser('calc')
verify_parser = subparsers.add_parser('verify')- 分离
calc和verify逻辑 - 自动生成帮助信息(
-h)
三、典型工作流程
场景1:单文件验证
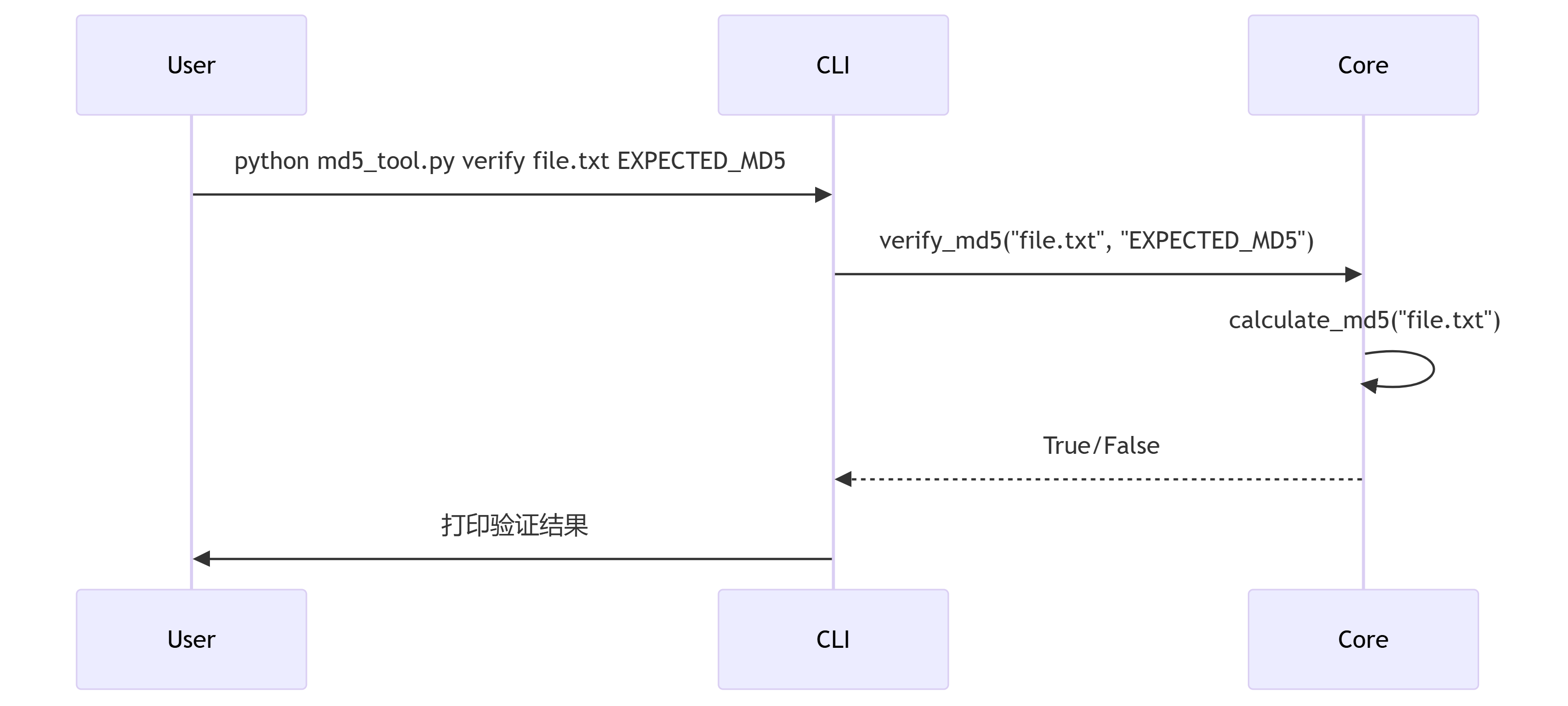
场景2:生成验证文件
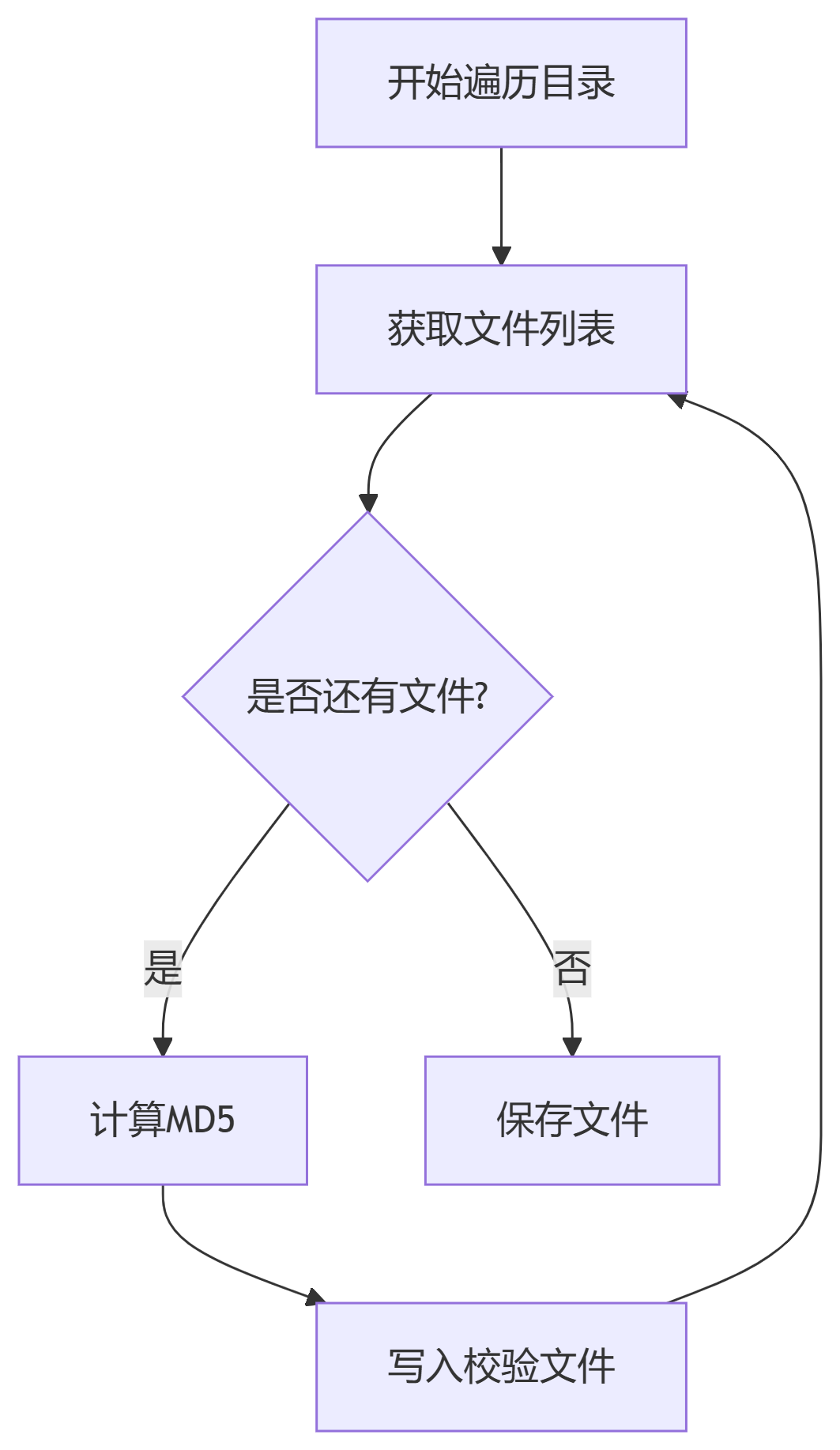
四、扩展设计思路
1. 算法扩展点
def calculate_hash(file_path, algorithm='md5', block_size=65536):
hasher = hashlib.new(algorithm) # 动态选择算法
# ...相同处理逻辑...2. 性能优化方向
- 并行计算:使用
concurrent.futures加速批量处理 - 进度显示:添加
tqdm进度条
3. 安全增强
- 签名校验:支持PGP签名验证
- 哈希链:实现类似
git的对象哈希链
4. 工程化改进
- 单元测试:针对大文件/空文件/非法路径等边界条件
- 日志记录:添加
logging模块记录操作
五、设计权衡考量
- 内存 vs 速度:
- 选择64KB块大小而非一次性读取
- 牺牲少量速度换取内存安全性
- 灵活性 vs 复杂度:
- 不默认支持多算法保持简单性
- 但保留扩展接口
- 严格模式可选:
- 当前大小写不敏感验证
- 可添加
--strict参数启用严格匹配
六、最终代码呈现
#!/usr/bin/env python3
import hashlib
import argparse
import os
import sys
from typing import Dict, List, Optional
# 常量定义
DEFAULT_BLOCK_SIZE = 65536 # 64KB块大小
MD5_FILE_EXTENSION = '.md5'
def calculate_md5(file_path: str, block_size: int = DEFAULT_BLOCK_SIZE) -> Optional[str]:
"""
计算文件的MD5哈希值
:param file_path: 文件路径
:param block_size: 读取块大小(字节)
:return: MD5字符串(失败返回None)
"""
if not os.path.isfile(file_path):
print(f"错误: 文件不存在 - {file_path}", file=sys.stderr)
return None
md5 = hashlib.md5()
try:
with open(file_path, 'rb') as f:
for block in iter(lambda: f.read(block_size), b''):
md5.update(block)
return md5.hexdigest()
except (IOError, PermissionError) as e:
print(f"错误: 无法读取文件 {file_path} - {str(e)}", file=sys.stderr)
return None
def batch_calculate_md5(file_list: List[str]) -> Dict[str, Optional[str]]:
"""
批量计算MD5值
:param file_list: 文件路径列表
:return: 字典{文件路径: MD5值}
"""
return {file_path: calculate_md5(file_path) for file_path in file_list}
def verify_md5(file_path: str, expected_md5: str) -> bool:
"""
验证文件MD5值
:param file_path: 文件路径
:param expected_md5: 预期MD5值
:return: 是否匹配
"""
actual_md5 = calculate_md5(file_path)
if actual_md5 is None:
return False
is_match = actual_md5.lower() == expected_md5.lower()
print(f"文件: {os.path.abspath(file_path)}")
print(f"预期MD5: {expected_md5.lower()}")
print(f"实际MD5: {actual_md5.lower()}")
print(f"验证结果: {'匹配' if is_match else '不匹配'}")
return is_match
def generate_md5_file(directory: str, output_file: str = None) -> bool:
"""
生成目录的MD5校验文件
:param directory: 目录路径
:param output_file: 输出文件路径(默认: 目录名.md5)
:return: 是否成功
"""
if not os.path.isdir(directory):
print(f"错误: 目录不存在 - {directory}", file=sys.stderr)
return False
if output_file is None:
output_file = os.path.basename(directory.rstrip('/\\')) + MD5_FILE_EXTENSION
try:
with open(output_file, 'w', encoding='utf-8') as f_out:
for root, _, files in os.walk(directory):
for filename in files:
file_path = os.path.join(root, filename)
md5 = calculate_md5(file_path)
if md5:
relative_path = os.path.relpath(file_path, directory)
f_out.write(f"{md5} *{relative_path}\n")
print(f"成功生成校验文件: {os.path.abspath(output_file)}")
return True
except IOError as e:
print(f"错误: 无法写入校验文件 - {str(e)}", file=sys.stderr)
return False
def verify_md5_file(md5_file: str) -> bool:
"""
验证MD5校验文件中的所有条目
:param md5_file: 校验文件路径
:return: 是否全部验证通过
"""
if not os.path.isfile(md5_file):
print(f"错误: 校验文件不存在 - {md5_file}", file=sys.stderr)
return False
all_passed = True
try:
with open(md5_file, 'r', encoding='utf-8') as f:
for line_num, line in enumerate(f, 1):
line = line.strip()
if not line or line.startswith('#'):
continue
# 解析格式: MD5 *文件名 或 MD5 文件名
parts = line.split(maxsplit=1)
if len(parts) != 2:
print(f"警告: 第{line_num}行格式错误 - {line}", file=sys.stderr)
all_passed = False
continue
expected_md5, file_path = parts
if file_path.startswith('*'):
file_path = file_path[1:]
if not verify_md5(file_path, expected_md5):
all_passed = False
except IOError as e:
print(f"错误: 读取校验文件失败 - {str(e)}", file=sys.stderr)
return False
return all_passed
def setup_argparse() -> argparse.ArgumentParser:
"""配置命令行参数解析"""
parser = argparse.ArgumentParser(
description='MD5校验工具',
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""使用示例:
计算MD5: %(prog)s calc file.txt
验证文件: %(prog)s verify file.txt d41d8cd98f00b204e9800998ecf8427e
生成校验: %(prog)s gen ./directory
验证校验: %(prog)s check checksums.md5"""
)
subparsers = parser.add_subparsers(dest='command', required=True, help='子命令')
# calc 子命令
calc_parser = subparsers.add_parser('calc', help='计算文件MD5值')
calc_parser.add_argument('file', help='目标文件路径')
# verify 子命令
verify_parser = subparsers.add_parser('verify', help='验证文件MD5值')
verify_parser.add_argument('file', help='要验证的文件路径')
verify_parser.add_argument('md5', help='预期的MD5值')
# gen 子命令
gen_parser = subparsers.add_parser('gen', help='生成目录的MD5校验文件')
gen_parser.add_argument('directory', help='目标目录路径')
gen_parser.add_argument('-o', '--output', help='输出文件路径')
# check 子命令
check_parser = subparsers.add_parser('check', help='验证MD5校验文件')
check_parser.add_argument('md5_file', help='MD5校验文件路径')
return parser
def main():
parser = setup_argparse()
args = parser.parse_args()
if args.command == 'calc':
md5 = calculate_md5(args.file)
if md5:
print(md5)
else:
sys.exit(1)
elif args.command == 'verify':
if not verify_md5(args.file, args.md5):
sys.exit(1)
elif args.command == 'gen':
if not generate_md5_file(args.directory, args.output):
sys.exit(1)
elif args.command == 'check':
if not verify_md5_file(args.md5_file):
sys.exit(1)
if __name__ == '__main__':
main()参考文章: