Large Language Models for Code:Security Hardening and Adversarial Testing论文学习笔记
Title: Large Language Models for Code:Security Hardening and Adversarial Testing
Author: Jingxuan He, Martin Vechev (ETH Zurich)
Conference: ACM CCS 2023
PDF: https://arxiv.org/pdf/2302.05319
一、研究背景与动机
随着大型语言模型(LLMs)在代码生成领域的广泛应用(如 CodeGen、Codex),“用AI写代码”变得越来越普遍。但已有研究指出,LLM 生成的代码中有相当比例存在安全漏洞(如内存问题、输入验证不足等)。
这种潜在风险在工业场景尤其严重,因为开发者往往会直接复用生成结果。
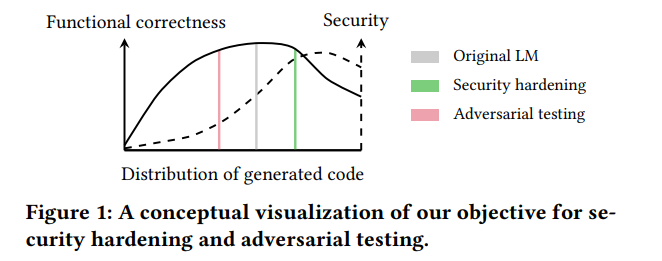
他们的工作中回答了三个问题:
-
如何让 LLM 生成的代码更安全?
-
是否可以控制 LLM 主动生成“脆弱代码”用于攻防测试?
-
能否在不修改 LLM 大模型权重的前提下实现上述控制?
二、研究任务:受控代码生成
本文将任务定义为:模型除了接收普通的 prompt 外,还接收一个 属性标记 c ∈ {sec, vul},用于指示生成代码应为“安全(sec)”还是“易脆弱(vul)”。
- 当 c = sec 时,目标是生成安全且功能正确的代码。
- 当 c = vul 时,目标是生成带漏洞的代码,用于对抗测试。
与此同时,保持模型的 功能正确性(functional correctness) 是关键,因为即便生成安全代码也必须能正常工作,生成带漏洞的代码也必须可运行,才能具备测试价值。
应用:
Security Hardening: 保证生成代码在功能正确的同时更安全
Adversarial Testing: 主动生成包含漏洞的代码,用于测试代码审计体系的鲁棒性
三、核心方法
为实现上述任务,作者提出了名为 SVEN (Security‐driven module) 的方法。其核心在于:
- 使用 prefix tuning(前缀调优):在原有 LLM 的输入前加入可训练的连续向量(prefix),而 冻结原 LLM 的参数。
- 分别为 “安全”与 “脆弱” 两个属性训练两个前缀: 与 。
- 在推理时,根据用户传入的属性 c 来选用对应前缀,从而控制模型输出的安全/脆弱特性。
该设计具备模块化、低成本、不改变原模型权重等优点,便于实际部署。
四、数据集构建
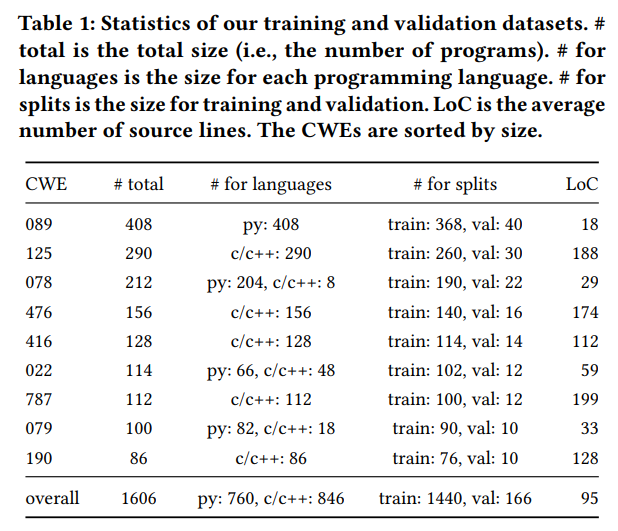
作者从现有漏洞库中筛选、清洗出了高质量的修复对(unsafe → fixed),共有约 803 对、共计约 1.6K 程序,覆盖 9 类典型 CWE(漏洞分类)。
此举的意义在于:虽然有大量漏洞数据集可用,但不少包含噪声(如重构、非安全变更等),若直接用于训练可能影响模型学习到错误的“vul模式”。因此,精挑细选、高质量数据是本研究成功的关键。
下图是一个例子:

五、训练细节与损失设计
训练目标分为三大类:
- 语言建模损失(LM‐Loss):对修复对中“变化区”(从unsafe → fixed所改动的 tokens)进行监督,促使模型在安全前缀下学习“正确”“安全”的写法,在脆弱前缀下学习“漏洞模式”。
- 对比损失(Contrastive‐Loss):使得 与 在特征空间中区分开来,保证两种前缀生成行为的差异化。
- KL 正则(KL‐Loss):对于“未改变区”(unsafe 和 fixed 中共通的部分),限制当前模型分布与原模型分布的距离,确保模型改变安全特性同时不破坏原有功能正确性。
通过三者结合,模型能够在代码“功能正确性”和“安全性”之间取得平衡。
六、实验结果
- 基于 CodeGen 2.7B 模型:原始模型在 “生成安全代码” 的比例仅约 59.1%。
- 使用 SVEN‐sec 前缀后,该比例提升至约 92.3%。
- 使用 SVEN‐vul 前缀后,“生成漏洞代码”的比例约为 36.8%。
- 在代码功能正确性(如 HumanEval 等)上,模型使用前缀后的表现与原模型相近,说明功能能力基本保留。
这些结果表明:SVEN 在强化安全特性(或生成漏洞)方面效果显著,同时保持了代码生成模型的实用性。
七、应用场景
- 安全性增强(Hardening):在实际代码生成辅助工具中,引入 p_sec 以降低生成漏洞代码的风险。
- 对抗测试(Adversarial Testing):利用 生成脆弱代码,用于评估代码审核、静态分析工具、开发者流程的鲁棒性。
八、优点与限制
优点:
- 模型结构轻量、无需改变模型权重,不需重新训练大模型。
- 明确控制生成代码的“安全”或“漏洞”属性。
- 保证功能正确性的同时增强安全或制造漏洞。
限制:
- 数据集相对规模较小且覆盖类别有限。
- 仅覆盖 9 类 CWE,不一定涵盖所有安全场景。
- 虽然前缀控制有效,但更复杂或系统级漏洞可能仍难以完全覆盖。
- 脆弱前缀有潜在滥用风险。
- 缺乏其他语言支持。
九、个人收获
- 学会将“生成属性控制”作为模型能力扩展:不仅仅生成“正确代码”,还能生成“满足某个属性”的代码。
- prefix tuning 是一种极具价值的“轻量可控”方法。
- 数据质量与任务定义在安全方向尤为重要——漏洞识别、修复对的构建需严谨。
- 在实用工具设计中,安全与功能正确性两者必须兼顾。
- 未来可考虑将“性能优化”“可读性”“风格一致性”等属性引入类似控制机制。