【论文笔记】Large Language Models for Code:Security Hardening and Adversarial Testing
Table of Contents
基本信息
Title: Large Language Models for Code:Security Hardening and Adversarial Testing
Author: Jingxuan He, Martin Vechev (ETH Zurich)
Conference: ACM CCS 2023
PDF: https://arxiv.org/pdf/2302.05319
该文章提出了一种用于代码生成大模型的安全硬化与评估的创新框架,其核心是通过静态的安全前缀引导为模型注入安全知识,并首创性地通过对抗性前缀生成来评估该防护的鲁棒性。其创新点在于敏锐地洞察到,传统的、基于规则的安全提示在面对自适应攻击时可能存在盲区,因此设计了一个“攻防一体”的闭环评估系统:一方面,利用漏洞扫描结果从知识库中匹配修复指令作为安全前缀,对模型进行安全加固;另一方面,训练一个攻击者模型,利用强化学习自动生成能诱导模型写出漏洞代码的对抗性前缀,以此对防御效果进行对抗性测试。这套方法将模型安全性的讨论,从“安全加固”是否有效提升到了在“何种攻击下会失效”,为构建可信的代码助手提供了自动化的评估范式和可量化的基准。
引言
大型语言模型(Large Language Models, LLMs)在训练了海量代码数据后,已展现出强大的代码生成能力,正逐步成为软件开发的重要辅助工具。然而,这些模型在训练过程中缺乏明确的安全目标,其生成代码的安全性存在严重隐患,可能无意中引入漏洞,给软件安全带来新的风险。当前,如何系统地提升代码生成模型的安全性(安全加固),以及如何严格评估其在恶意诱导下的鲁棒性(对抗测试),是两个至关重要却未被充分探索的维度。本文旨在通过提出一个名为可控代码生成的新任务,来统一应对这两个挑战。该任务以二元安全属性为参数,在不损害模型功能正确性的前提下,精准引导模型生成安全或不安全的代码。为此,我们提出了一种名为SVEN的新型学习框架。SVEN通过学习特定属性的连续向量来引导代码生成,无需修改基础模型权重,从而实现了高效、灵活的安全控制。实验表明,SVEN能极大增强模型的安全性:例如,它将一个先进的2.7B参数CodeGen模型生成安全代码的比例从59.1%显著提升至92.3%,反之,在进行对抗性测试时,也能将其安全生成率有效降至36.8%,同时SVEN在功能正确性方面与原始语言模型非常接近。
背景与动机
1. 代码生成模型的兴起与安全隐患
在自然语言领域取得巨大成功之后,在大规模代码库上预训练的大型语言模型(如Codex、CodeGen)已能根据自然语言描述生成功能复杂的代码片段,极大地提升了开发效率。然而,这些模型的训练目标主要是学习代码的语法与功能模式,其训练数据中不可避免地混合着大量含有已知或未知漏洞的不安全代码。这导致模型缺乏内在的“安全意识”,在生成过程中会不加判别地复现这些不安全模式,频繁产生诸如SQL注入、缓冲区溢出等常见漏洞的代码,使其在实际应用,尤其是安全敏感场景中,存在巨大的部署风险。
2. 现有安全研究的局限性
当前针对代码模型安全性的研究主要分为两个方向,但均存在不足。一方面,安全加固方向的工作(如基于规则的安全提示、代码后处理过滤)往往依赖于静态、固化的知识,泛化能力弱,且容易影响生成代码的功能正确性。另一方面,安全评估方向的工作大多依赖于有限的测试用例或简单的恶意提示,缺乏系统性、自适应的方法来探索模型安全边界,难以全面评估其在面对针对性攻击时的真实鲁棒性。这两个方向通常被割裂研究,缺乏一个统一的框架来同时实现有效的安全提升和严格的安全评估。
3. 本文的动机与核心思路
基于上述缺口,本文的核心动机是:能否构建一个统一的、参数化的框架,以可控的方式引导模型的安全属性,从而无缝衔接安全加固与对抗测试? 我们提出一个受控代码生成任务。该任务的关键在于,引导必须是精确的(能显著改变安全属性)、保真的(不影响功能正确性)且高效的(无需重训练大模型)。为此,我们提出了SVEN框架,其核心思想是学习一个轻量的、可插拔的“安全导向器”,通过属性特定的连续向量在推理时动态影响模型的生成概率分布。我们通过精心构建的数据集和专门的损失函数来训练这个导向器。这一设计使得我们既能将模型“硬化”为安全版本,也能模拟攻击者视角将其“弱化”为不安全版本,从而在一个框架内完成防御能力的提升与攻破深度的评估,为理解与保障代码生成模型的安全性提供了全新的视角与工具。
主要挑战
C1:模块化(Challenge I: Modularity)
由于现有大语言模型参数量巨大,对其进行重新预训练或微调(即修改全部模型权重)的成本过高。因此,我们期望训练一个独立的、可插拔的模块来实现安全控制,而无需覆盖或修改基础大模型的权重。同时,鉴于高质量安全漏洞数据获取困难,该方法还必须能够在少量数据上进行高效训练。
C2:功能正确性与安全控制的权衡(Challenge II: Functional Correctness vs. Security Control)
实施安全控制时,必须保持模型生成功能正确代码的能力。对于安全加固,这确保了模型的实用性;对于对抗测试,保持功能正确性对于攻击的隐蔽性至关重要。一个安全可控但功能严重受损的模型几乎没有实用价值,因为它容易被最终用户察觉并弃用。核心挑战在于设计一种能同时实现强安全控制和高功能正确性双重目标的训练机制。
C3:确保高质量训练数据 (Challenge III: Ensuring High-quality Training Data)
训练数据的质量至关重要。数据必须与我们的代码补全任务设置对齐并具有泛化性,且必须精确捕捉真实的安全修复逻辑。为了避免模型学习到无关的代码模式(如代码重构或功能性修改),必须排除这些无关的代码变更。尽管已有一些漏洞数据集,但它们不完全适用于本任务,甚至存在严重的数据质量问题。因此,我们必须分析现有数据集的适用性,并据此构建高质量的训练数据。
SVEN的设计与实现
1. 核心架构:模块化的连续前缀引导
SVEN的核心是一种轻量级、可插拔的适配器方法。它保持基础大语言模型的权重完全不变,通过为每个安全属性(安全/不安全)学习一组属性特定的连续向量序列(即“前缀”)来实现控制。在生成时,将对应属性的前缀作为初始隐藏状态输入模型,通过注意力机制影响后续所有隐藏状态的计算,从而在连续表示空间中“提示”模型生成符合目标属性的代码。因其参数量极小(仅为基础模型的约0.1%),SVEN实现了高效训练与部署的模块化。
2. 训练策略:分区域优化以实现双重目标
为实现“安全控制”与“保持功能正确性”的平衡,SVEN采用了分区域的专业化损失函数进行训练:
- 在用于训练的安全修复数据(漏洞代码/修复后代码对)中,被修改的代码区域对安全属性具有决定性,而未修改的区域则是中性的。
- 应用条件语言建模损失和安全-漏洞对比损失,以强化模型在该区域生成目标属性代码的能力。
- 应用基于KL散度的损失,约束前缀在该区域产生的下一个词元概率分布与原模型保持一致,从而保留模型的原始功能正确性。
3. 数据基础:高质量、精筛选的训练集
SVEN的有效性依赖于高质量数据。论文指出现有漏洞数据集存在泛化性不足或掺杂无关代码变更的问题。为此,作者对多个开源数据集进行了人工审查与精炼,最终构建了一个规模较小(约1.6k程序对)但质量极高的专用数据集。实验证明,该小规模高质量数据集的表现显著优于盲目包含更多低质量数据(约19倍)的基线,体现了数据质量重于数量的原则。
4. 关键特性与效果
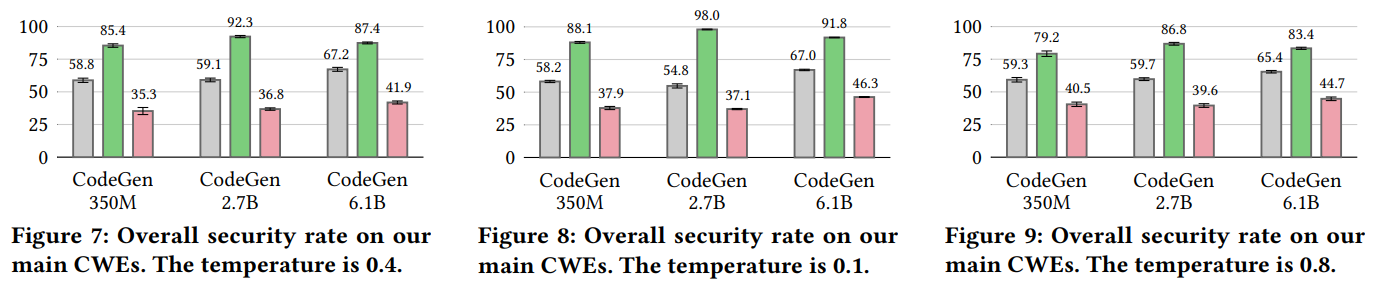
- 强安全控制:在2.7B参数的CodeGen模型上,能将生成安全代码的比例从基线的59.1%,通过安全加固显著提升至92.3%,或通过对抗测试有效降低至36.8%。
实验设置
本文通过系统的实验评估SVEN在安全控制与功能正确性两方面的表现。
1. 评估任务与目标
实验核心围绕 “受控代码生成” 任务展开,具体评估以下两个维度:
-
安全加固:验证SVEN能否引导模型生成更安全的代码。
-
对抗测试:验证SVEN能否引导模型生成更不安全的代码(用于评估防护的鲁棒性)。 所有实验均在保持模型原有功能正确性的前提下进行。
2. 评估数据集与漏洞选择
为确保评估的全面性与现实性,本文构建了一个高质量的测试集:
- 漏洞类型:覆盖了9类关键且常见的CWE漏洞,包括:
- SQL注入(CWE-89)
- 路径遍历(CWE-22)
- 操作系统命令注入(CWE-78)
- 跨站脚本(CWE-79)
- 越界读写(CWE-125, CWE-787)
- 空指针解引用(CWE-476)
- 整数溢出(CWE-190)
- 释放后重用(CWE-416)
- 场景设计:每类漏洞下设计了多个不同的代码场景(共18个测试场景),涵盖Python和C两种语言,以模拟真实的编程任务。
- 数据划分:每个CWE下的场景被进一步划分为测试集与验证集,防止模型过拟合到特定代码片段。
3. 基线模型与目标模型
- 基础模型:实验主要在以CodeGen家族的多规模模型(350M, 2.7B, 6.1B参数)上进行,以检验方法在不同模型容量下的有效性。
- 对比基准:以未经过任何安全控制的原始CodeGen模型作为主要性能基线。
4. 评估指标
- 安全率:在给定漏洞场景下,模型生成的安全代码样本占总生成样本的百分比。这是衡量安全控制能力的核心指标。
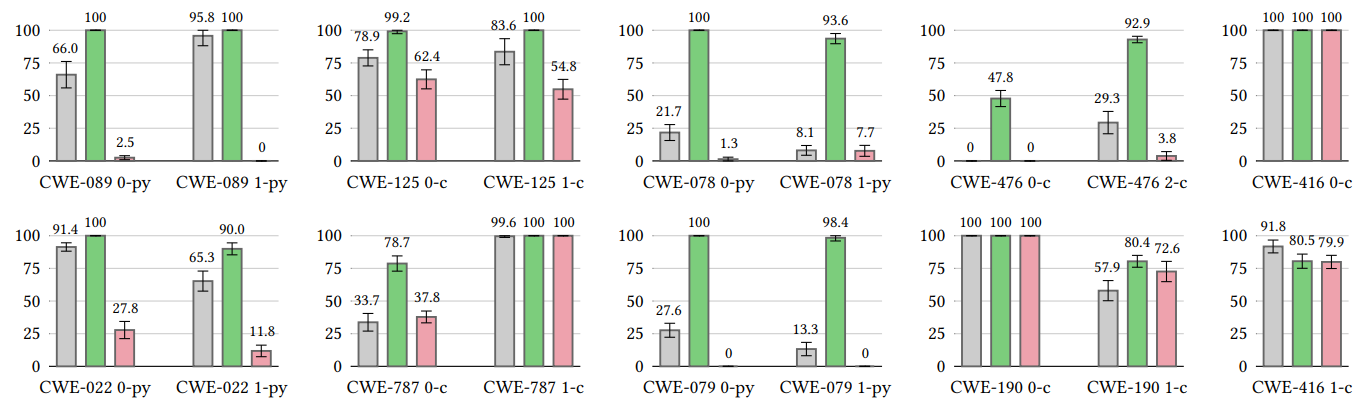
- 功能正确率:使用HumanEval基准测试的pass@k得分,评估模型生成代码的功能正确性是否因安全控制而下降。
![Table 3: Comparison between CodeGen LMs [57] and SVEN
on the ability to generate functionally correct code, measured
by pass@𝑘 scores on the HumanEval benchmark [26].](/images/sven/table3.png)
5. 实验配置
-
解码温度:为了检验方法在不同生成随机性下的稳定性,实验在两个不同的温度值下进行:0.4(兼顾多样性与确定性)和0.1(高确定性、低随机性)。
-
控制方式:实验中,通过切换SVEN学习的安全前缀与不安全前缀,使同一个基础模型能在安全加固与对抗测试两种模式下运行。
总结
本研究针对代码生成大模型频繁生成不安全代码问题,提出一个可控的安全研究范式。通过定义受控代码生成这一任务,将安全加固和对抗性测试整合到同一个框架下。为解决该任务,本文设计了SVEN这一轻量级解决方案,其核心在于:
- 1)模块化架构:通过学习属性特定的连续前缀来引导生成方向,无需修改大模型权重;
- 2)精准的训练策略:利用分区域损失函数,在代码的修改区域强化安全控制,在未变区域保持功能正确性;
- 3)高质量数据基础:通过人工精炼构建专用数据集,确保了方法的有效性。
全面的实验评估表明,SVEN能够以“开关”式的精准控制,在覆盖多种高危漏洞(CWE)的测试集上,显著提升或降低模型的安全生成率(例如,将某模型的安全率从59.1%提升至92.3%或降至36.8%),同时几乎完全保持模型原有的功能正确性。这项工作不仅为提升现有AI编程助手的安全性提供了切实可行的技术路径,更重要的是,它在保持功能正确性的严格约束下,为代码模型建立了系统性的对抗评估基准。
研究的局限性和未来方向
本研究虽提出了创新的框架,但仍存在若干局限,这些局限恰恰指明了有价值的未来工作方向:
-
- 泛化能力的局限:SVEN的有效性目前主要在Python和C/C++语言的特定CWE漏洞上得到验证。对于训练数据未覆盖的漏洞类型及其他编程语言,其控制能力可能下降。未来需构建更全面、多样化的安全修复数据集,可借助自动化安全分析工具或众包平台来扩充数据。
-
- ……